Exploring the cuBLAS library for ACT on GPU
In this post we will explore my further attempts to optimize the ACT library for CUDA, on the way to potentially writing my own kernel for the dictionary search. Even though I am not sure that a custom kernel would benefit the simplicity of the algorithm (matmul + argmax), I want to explore the possibilities and see how far I can get.
I decided to start looking at cuBLAS to see how it compares to the MLX on CUDA implementation.
In addition to performance profiling I will also look at specific CUDA profiling information using the NVidia ncu command line tool.
cuBLAS
The cuBLAS library is a high performance BLAS library for CUDA, it implements the BLAS API for CUDA. It is part of the CUDA Toolkit and is available on all NVIDIA GPUs.
The single signal searchDictionary function mirrors the CPU implementation, plus some memory management to handle the GPU memory.
// search_dictionary: GPU fast path for float, else CPU fallback
template <typename Scalar>
std::pair<int, Scalar> ACT_cuBLAS_T<Scalar>::search_dictionary(
const Eigen::Ref<const act::VecX<Scalar>>& signal) const {
if (this->get_dict_size() == 0) return {0, Scalar(0)};
#ifdef USE_CUDA
if constexpr (std::is_same_v<Scalar, float>) {
ensure_cuda_resources();
ensure_cuda_dict();
const int m = this->get_length();
const int n = this->get_dict_size();
// Upload x (float32) directly on the same stream as cuBLAS
cudaMemcpyAsync(d_x_, signal.data(), sizeof(float) * static_cast<size_t>(m), cudaMemcpyHostToDevice, stream_);
const float alpha = 1.0f;
const float beta = 0.0f;
// scores = A^T * x (A is m x n, column-major)
cublasStatus_t st = cublasSgemv(handle_, CUBLAS_OP_T,
m, n,
&alpha,
d_A_, m,
d_x_, 1,
&beta,
d_scores_, 1);
if (st != CUBLAS_STATUS_SUCCESS) {
throw std::runtime_error("cublasSgemv failed in ACT_cuBLAS::search_dictionary");
}
// Argmax by magnitude
int best_idx_1based = 1;
st = cublasIsamax(handle_, n, d_scores_, 1, &best_idx_1based);
if (st != CUBLAS_STATUS_SUCCESS) {
throw std::runtime_error("cublasIsamax failed in ACT_cuBLAS::search_dictionary");
}
int best_idx = best_idx_1based - 1;
// Fetch best value (signed)
float best_val = 0.0f;
cudaMemcpyAsync(&best_val, d_scores_ + best_idx, sizeof(float), cudaMemcpyDeviceToHost, stream_);
cudaStreamSynchronize(stream_);
return {best_idx, static_cast<Scalar>(best_val)};
}
#endif
// Fallback: CPU path
return Base::search_dictionary(signal);
}As a refresh, here is the dictionary search function using CPU BLAS from the previous posts:
template <typename Scalar>
std::pair<int,Scalar> ACT_CPU_T<Scalar>::search_dictionary(const Eigen::Ref<const act::VecX<Scalar>>& signal) const {
assert(signal.size() == length);
if (dict_size == 0) return {0, 0.0};
act::VecX<Scalar> scores(dict_size);
scores.setZero();
const int m = length;
const int n = dict_size;
const Scalar alpha = Scalar(1);
const Scalar beta = Scalar(0);
// scores = A^T * x (A is m x n, column-major)
act::blas::gemv_colmajor_trans(m, n,
alpha,
dict_mat.data(), m,
signal.data(), 1,
beta, scores.data(), 1);
// Find argmax by magnitude using BLAS IAMAX (max |value|)
int best_idx = act::blas::iamax(n, scores.data(), 1);
Scalar best_val = scores[best_idx]; // keep signed value for potential diagnostics
return {best_idx, best_val};
}MLX::Compile
For this test scenario I decided to try to use mlx::compile to see if mlx would further optimize the dictionary search function.
The code below shows how the search_fn is compiled the first time the search function is called using a C++ non-capturing lambda function (non-capturing means its stateless, it doesn’t capture any variables from the scope in which it is defined … had to look that up)
template <typename Scalar>
std::pair<int, Scalar> ACT_MLX_T<Scalar>::search_dictionary(const Eigen::Ref<const act::VecX<Scalar>>& signal) const {
if (this->get_dict_size() == 0) return {0, Scalar(0)};
#ifdef USE_MLX
// Only enable MLX fast path for float precision
if constexpr (std::is_same_v<Scalar, float>) {
// Lazily ensure MLX dictionary is available
ensure_mlx_dict();
const int m = this->get_length();
const int n = this->get_dict_size();
// Upload signal as float32 1D array directly from Eigen data (one host->device copy)
mx::array x_arr(const_cast<float*>(signal.data()), mx::Shape{m}, mx::float32);
// Lazily compile the search function once per instance
if (!search_fn_) {
search_fn_ = mx::compile([](const std::vector<mx::array>& inputs) {
const mx::array& A = inputs[0];
const mx::array& x = inputs[1];
auto scores = mx::matmul(mx::transpose(A), x); // {n}
auto idx = mx::argmax(scores);
auto best = mx::take(scores, idx);
return std::vector<mx::array>{idx, best};
});
}
// Compiled path: call compiled function with inputs [A, x]
// Returns vector<array> with [idx, best_val]
std::vector<mx::array> outs = search_fn_({*dict_gpu_, x_arr});
auto idx_arr = outs[0];
auto best_val_arr = outs[1];
int best_idx = idx_arr.template item<int>();
float best_val_f = best_val_arr.template item<float>();
return {best_idx, static_cast<Scalar>(best_val_f)};
}
#endif
// Fallback: CPU (Accelerate) path
return Base::search_dictionary(signal);
}Performance Profiling results
- Mac : Apple MacBook Pro M1 Max 32GB running MacOS 14.6
-
PC : custom built Intel Core i9 14th gen, 64GB RAM, NVIDIA RTX 4090 running Ubuntu 24.04.
- ACT : the reference ACT implementation using standard library functions
- MLX : the ACT implementation using Apple MLX
-
cuBLAS : the ACT implementation using cuBLAS
- double : double precision (
double|double64) -
single : single precision (
float|float32) - Dict Search : a single dictionary search operation on its own
- Transform : the full transform operation at order 10, this includes the dictionary search operations and the BFGS optimization at each turn
- SNR : Signal to Noise Ratio, higher is better
| System | Dict Search Mean (ms) | Dict Search Range (ms) | Transform Mean (ms) | Transform Range (ms) | SNR Mean (dB) | SNR Range (dB) |
|---|---|---|---|---|---|---|
| Mac / MLX / single | 4.22 | [4.03, 5.93] | 57.25 | [52.61, 63.48] | 10.89 | [10.31, 11.39] |
| PC / MLX / single | 1.82 | [1.60, 2.50] | 36.14 | [26.89, 42.05] | 10.88 | [9.89, 12.16] |
| PC / cuBLAS / single | 1.38 | [1.30, 2.19] | 24.76 | [21.81, 29.37] | 11.10 | [9.99, 12.42] |
The cuBLAS implementation is approximately 20% faster than the MLX implementation on the same hardware, which prompted the following investigation into the CUDA kernels used by the two libraries.
CUDA profiling with ncu
I used the ncu tool to profile the two implementations and compare the kernels used by the two libraries.
This is as simple as : sudo ncu -o <output_file> <binary>
sudo was required for my system (ubuntu 24.04) to get access to the metrics.
The first image below shows the report from the cuBLAS execution.

cuBLAS uses a gemv kernel and an iamax kernel executed twice, possibly a multipass implementation.
The second image below shows the report from the MLX with CUDA backend execution.
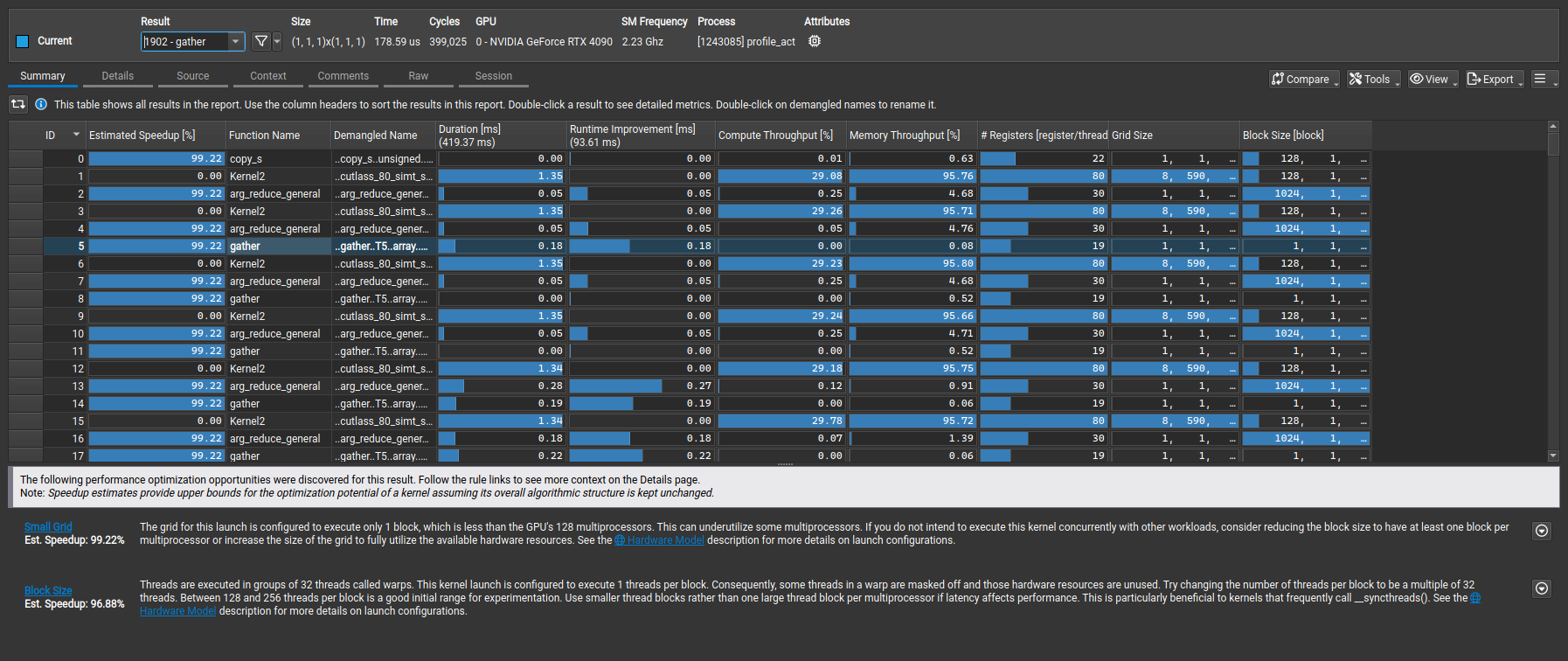
The MLX compiled graph uses these three kernels :
void cutlass::Kernel2<cutlass_80_simt_sgemm_128x32_8x5_nn_align1>(Params)void mlx::arg_reduce_general<float..ArgMax..1024..const T1 *, unsigned int..long, cuda::array..void mlx::gather<float, unsigned int, 1, 0..const T1..T5, cuda::array..long..T3..T2..T4..
The cutlass kernel is in the ballpark of the cuBLAS implementation, but it seems like the arg_reduce_general plus gather kernels are not as optimized as the multipass cuBLAS iamax kernel.
The code for the MLX arg_reduce_general kernel is here : mlx::arg_reduce_general on github
The MLX gather kernel code is here : mlx::gather on github
Maybe next is a deep dive into those kernels.